
AiPrise
17 min read
December 18, 2025
Guide to Understanding Fraud Detection Rules

Key Takeaways

In 2024, consumers and businesses reported losing more than $12.5 billion to fraud, a 25% increase over the prior year. This highlights how criminal tactics are rapidly changing and outpacing traditional defenses. For your business, especially if you operate in financial services, payments, or crypto, that shift is a real problem you’re fighting every day.
Fraud attacks today don’t look like they did a decade ago; they move faster, exploit gaps in rule sets, and hide inside legitimate transactions, leaving risk teams scrambling to stay ahead. You already use rule-based controls in your risk engine, but as fraud tactics evolve quickly, it’s crucial to understand how these rules work to control losses and false positives.
In this guide, you’ll learn exactly what fraud detection rules are, how they function inside risk systems, what they catch, and how to apply them effectively in 2026.
Key Takeaways - At a Glance
- Fraud detection rules help control risk by enforcing clear, explainable logic across onboarding, transactions, and account activity.
- Rule-based systems are effective at catching repeatable fraud patterns like velocity abuse, account takeover signals, and payment anomalies.
- Relying only on rules creates blind spots, as static logic struggles with changing tactics and complex user behavior.
- Combining rules with machine learning improves adaptability, prioritization, and detection accuracy at scale.
- AiPrise enhances fraud rule performance by strengthening identity verification, KYC, KYB, AML screening, and global risk intelligence.
What Are Fraud Detection Rules and Why Do They Matter?
Fraud detection rules are the first layer of control you use to decide what activity deserves scrutiny and what should pass without friction. If you handle payments, onboard users, or manage regulated flows, these rules help you translate risk appetite into enforceable logic.
Without them, your systems either trust everything or overreact to normal behavior. Neither works when you are balancing growth, compliance, and customer experience at scale.
Below are the core reasons these rules matter in your risk stack.
- They Convert Risk Policy Into Action: You define what is acceptable and what is not, then enforce it consistently across transactions, logins, and onboarding flows.
- They Enable Immediate Decisions: Rules let you block, step up, or allow activity instantly, which is critical when milliseconds affect fraud losses or customer drop-offs.
- They Create Explainable Outcomes: When a transaction is flagged, you can trace exactly which condition triggered it, helping audits, regulators, and internal reviews.
- They Protect High-Value Moments: You can apply stricter logic to events like first transactions, account changes, or large payouts where fraud impact is highest.
- They Reduce Operational Noise: Well-designed rules filter obvious risk, so your analysts focus on complex cases instead of reviewing everything manually.
Also read: How to Detect Financial Services Fraud: A Practical Guide for Businesses
Understanding the importance of fraud detection rules sets the stage for implementing the most essential rules in 2026.
Top 8 Essential Fraud Detection Rules for 2026
In 2026, fraud pressure is shifting toward speed, coordination, and abuse of trusted infrastructure. You are no longer just dealing with single bad actors but with automated networks testing your controls at scale. The rules that worked two years ago often fail because fraudsters now probe thresholds, rotate identities, and blend into legitimate traffic.
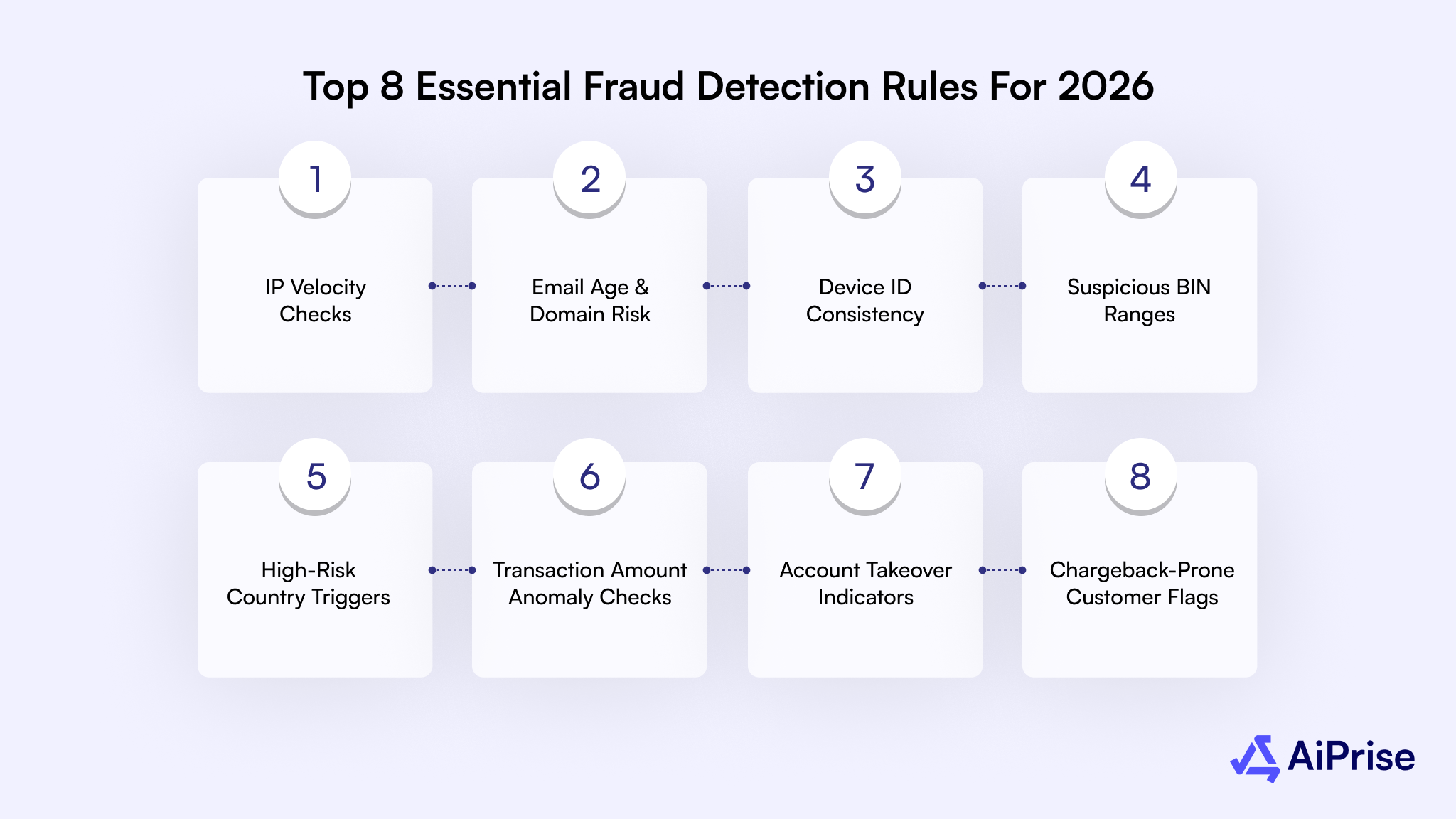
Below are the most critical fraud detection rules you should prioritize and why each one still matters this year.
IP Velocity Checks
IP velocity checks focus on how quickly activity accumulates from the same IP address across a short time window. This rule becomes critical as fraud rings rely on automation to test signups, logins, and payments in rapid bursts.
When traffic looks normal at a single-event level but abnormal in aggregate, velocity is often the first signal that exposes coordinated abuse. For platforms handling onboarding, payments, or account access, this rule helps surface intent before financial damage occurs.
Below are the core ways IP velocity checks protect your systems.
- Burst Activity Across Multiple Accounts: A single IP generating dozens of signups or payment attempts within minutes usually signals scripted behavior. Even when identities differ, this pattern reveals infrastructure reuse common in fraud farms.
- Rapid Transaction Attempts in Short Windows: High-frequency payment attempts from one IP often indicate card testing or balance probing. Catching this early prevents chargebacks and stops fraud before cards are fully exploited.
- Repeated Access to High-Risk Endpoints: Concentrated traffic hitting login, password reset, or OTP verification endpoints suggests account takeover preparation. Velocity helps identify this even when credentials appear valid.
- Proxy and VPN Abuse Detection: Fraudsters frequently rotate IPs through hosting providers, but velocity spikes still emerge when automation is misconfigured. Monitoring request speed alongside IP reputation strengthens this rule.
- Adaptive Thresholds by Business Flow: Signup flows, withdrawals, and payouts require different tolerance levels. Applying contextual velocity limits prevents unnecessary friction while still controlling high-impact abuse paths.
Seeing repeated activity from the same IP but unsure whether it’s real users or coordinated abuse? AiPrise helps strengthen velocity-based rules by validating identities in real time through its KYC solution, so rapid activity is assessed against verified user profiles.
Email Age and Domain Risk
Email verification and domain risk rules help you judge credibility before trust is extended. In regulated environments, email is often the first identifier tied to onboarding, payments, or account recovery.
Fraud operations frequently rely on newly created inboxes or low-quality domains because they are cheap, disposable, and hard to trace. When these signals are ignored, risky users enter your system quietly and surface later as losses, chargebacks, or compliance issues that are harder to reverse.
Below are the key ways this rule strengthens your fraud controls.
- Newly Created Email Detection: Emails created days or weeks ago often correlate with short-term fraud intent. Applying stricter checks at this stage reduces exposure during onboarding and first transactions.
- Disposable and Temporary Domain Filtering: Domains linked to throwaway email providers are commonly used for testing platforms. Flagging these early prevents abuse without waiting for transaction-level signals.
- Domain Reputation Assessment: Some domains show consistent links to fraud across industries. Incorporating reputation data helps block repeat abuse even when the individual's identity looks clean.
- Mismatch Between Email and User Profile: High-value transactions tied to generic or random-looking email formats often signal automation. Contextual review here protects sensitive flows like payouts or credit approvals.
- Risk-Based Step-Up Triggers: Older, trusted domains can pass with minimal friction, while newer or risky domains trigger additional verification. This keeps genuine users moving while controlling exposure.
Also Read: A Complete Guide to Money Laundering Scams in 2026

Device ID Consistency
Device ID consistency rules focus on whether the same physical or virtual device behaves in a stable, predictable way over time. In fraud-heavy environments, identities change easily, but devices are harder to rotate at scale. This rule helps you understand whether an account is acting from a trusted environment or masking its true origin during sensitive actions.
Below are the main ways device consistency protects your platform.
- Stable Device Behavior Over Time: Legitimate users usually return from the same device with minor variations. Sudden changes in device identifiers during logins or transactions raise credibility concerns.
- Multiple Accounts Linked To One Device: A single device accessing many accounts often points to farming activity. Detecting this early limits abuse across onboarding, referrals, and promotions.
- Unexpected Device Changes During High-Risk Actions: Device switches right before payouts, credential updates, or payment attempts signal possible account compromise. This rule helps stop damage at the critical moment.
- Emulator and Spoofing Signal Detection: Fraud setups often rely on emulators that generate inconsistent device attributes. Identifying these patterns reduces exposure to large-scale automated attacks.
- Contextual Trust Building: Consistent devices can be fast-tracked through low-risk flows, while unstable devices trigger step-up checks. This balances protection with user experience.
Suspicious BIN Ranges
Suspicious BIN range rules focus on patterns tied to the first digits of a payment card, which reveal the issuing bank, card type, and region. In fraud monitoring, certain BINs become high-risk over time due to repeated abuse, data breaches, or weak issuer controls. Ignoring these signals exposes payment flows to systematic exploitation.
Below are key ways BIN range monitoring improves fraud control.
- High-Fraud Issuer Identification: Some issuers consistently appear in confirmed fraud cases. Monitoring these BINs allows you to apply tighter controls where loss probability is already proven.
- Mismatch Between BIN and User Context: A card issued in one country used with an unrelated location or profile increases risk. This inconsistency often signals stolen card usage.
- Card Type Abuse Patterns: Prepaid or virtual cards from specific BINs are frequently used for testing or laundering. Flagging these reduces exposure during checkout and subscriptions.
- Breach-Exposed BIN Monitoring: After major data leaks, affected BINs see spikes in misuse. Temporary restrictions help contain damage while issuers rotate compromised cards.
- Selective Friction Application: Trusted BINs move smoothly, while risky ones trigger step-up checks. This approach protects revenue without hurting conversion rates.
Also Read: How to Detect Fraudulent Documents in KYB Verification
High-Risk Country Triggers
High-risk country triggers help you respond to jurisdiction-level risk that goes beyond individual behavior. Certain regions consistently appear in fraud, money laundering, or sanction-related cases due to regulatory gaps or organized networks.
Treating all locations equally increases exposure and weakens compliance controls. These rules allow you to apply country-aware logic without blocking legitimate cross-border activity that your business still depends on.
Below are the key ways country-based triggers protect your operations.
- Regulatory and Sanctions Alignment: Transactions involving restricted or closely monitored jurisdictions require stricter handling. Applying country triggers helps meet regulatory expectations without manual review.
- Cross-Border Usage Mismatches: Activity originating from countries unrelated to a customer’s profile often signals proxy usage or stolen credentials. Flagging these cases reduces silent account abuse.
- Abnormal Traffic Concentration: Sudden spikes from specific regions can indicate coordinated attacks. Early detection limits damage during large-scale fraud campaigns.
- Payment Corridor Risk Control: Some country-to-country payment paths show higher fraud rates. Applying tailored rules by corridor improves approval quality without blocking all foreign traffic.
- Context-Based Step-Up Decisions: Low-risk countries pass with minimal friction, while higher-risk regions trigger extra checks. This maintains global reach while controlling loss.
Transaction Amount Anomaly Checks
Transaction amount anomaly checks focus on whether the value of a transaction makes sense in context. Fraud rarely starts at a normal level. It often begins with unusually small amounts to test success, or sudden large amounts to maximize impact before detection.
If your platform processes payments, payouts, or credits, ignoring amount behavior allows fraud to blend into otherwise valid flows. This rule helps you spot intent by comparing value patterns, not just transaction approval status.
Below are the key ways amount-based anomaly checks reduce exposure.
- Sudden Spikes In Transaction Value: A sharp jump from low to high amounts often signals stolen credentials or compromised accounts. Applying limits here protects balances and merchant funds.
- Micro-Transaction Testing Patterns: Very small amounts repeated quickly usually indicate card testing. Catching this early prevents broader card misuse across your system.
- Amount Mismatch With User History: Transactions far outside a user’s normal range raise risk even if details look valid. Contextual thresholds reduce silent fraud.
- Category-Specific Value Controls: Different products carry different risks. Setting amount rules by category avoids overblocking while protecting high-loss scenarios.
- Progressive Risk Escalation: Higher amounts can trigger step-up checks instead of outright blocks. This preserves conversion while reducing financial impact.
Account Takeover Indicators
Account takeover indicators focus on changes that signal loss of legitimate control. These attacks rarely start with a transaction. They begin with subtle shifts in access patterns, recovery attempts, or profile changes that look harmless in isolation.
For platforms holding funds, personal data, or compliance obligations, missing these early signs leads to direct financial loss and regulatory exposure. This rule helps you intervene before attackers monetize access or move assets out.
Below are the most reliable signals of account takeover risk.
- Unusual Login Sequence Changes: Logins occurring at odd hours or from unfamiliar environments suggest credentials are being misused. Tracking these shifts helps surface compromise early.
- Rapid Credential or Profile Updates: Changes to passwords, emails, or phone numbers in quick succession often aim to lock out the real user. Blocking these sequences limits attacker control.
- Failed Authentication Followed By Success: Multiple failures followed by a successful login can indicate brute-force or credential stuffing attempts. This pattern deserves immediate attention.
- Behavior Drift After Access: Once inside, attackers act differently. Sudden changes in navigation, feature usage, or transaction intent often reveal takeover activity.
- High-Risk Actions Without Prior History: First-time withdrawals, payouts, or address changes raise concern when no prior pattern exists. Step-up checks here prevent irreversible loss.
Also Read: Common Red Flags In Fraud Detection
Chargeback-Prone Customer Flags
Chargeback-prone customer flags help you identify users who consistently generate post-transaction disputes and reversals. These cases are costly because damage appears weeks later, after funds have moved and operational effort has already been spent.
In payments and subscription-based models, repeated chargebacks often signal friendly fraud, abuse of refund policies, or masked criminal activity. Detecting this behavior early helps protect merchant relationships and keeps risk ratios within acceptable thresholds.
Below are key signals that indicate elevated chargeback risk.
- History of Disputed Transactions: Customers with repeated disputes show a pattern that cannot be ignored. Applying stricter review reduces future losses and network penalties.
- Mismatch Between Purchase And Usage Behavior: High-value purchases followed by minimal usage often precede chargebacks. This pattern suggests intent issues rather than service dissatisfaction.
- Frequent Refund And Reversal Requests: Excessive refund activity increases exposure even when fraud is not confirmed. Monitoring this behavior helps prevent abuse of support processes.
- Payment Method Switching Patterns: Changing cards after disputes can indicate evasion tactics. Flagging this behavior protects checkout flows from repeat abuse.
- Targeted Friction On High-Risk Profiles: Trusted customers proceed smoothly, while flagged profiles face added verification. This limits losses without affecting the broader user base.
With the top rules identified, it’s important to see how they function within a risk engine to protect transactions effectively.
How Do Fraud Detection Rules Work Inside a Risk Engine?
Inside a risk engine, fraud detection rules act as decision logic that evaluates activity the moment it enters your system. Every login, payment, or account change is assessed against conditions you define based on risk tolerance and compliance needs. These rules do not work in isolation.
They interact with data streams, scoring layers, and decision paths that determine whether an action proceeds, pauses, or escalates.
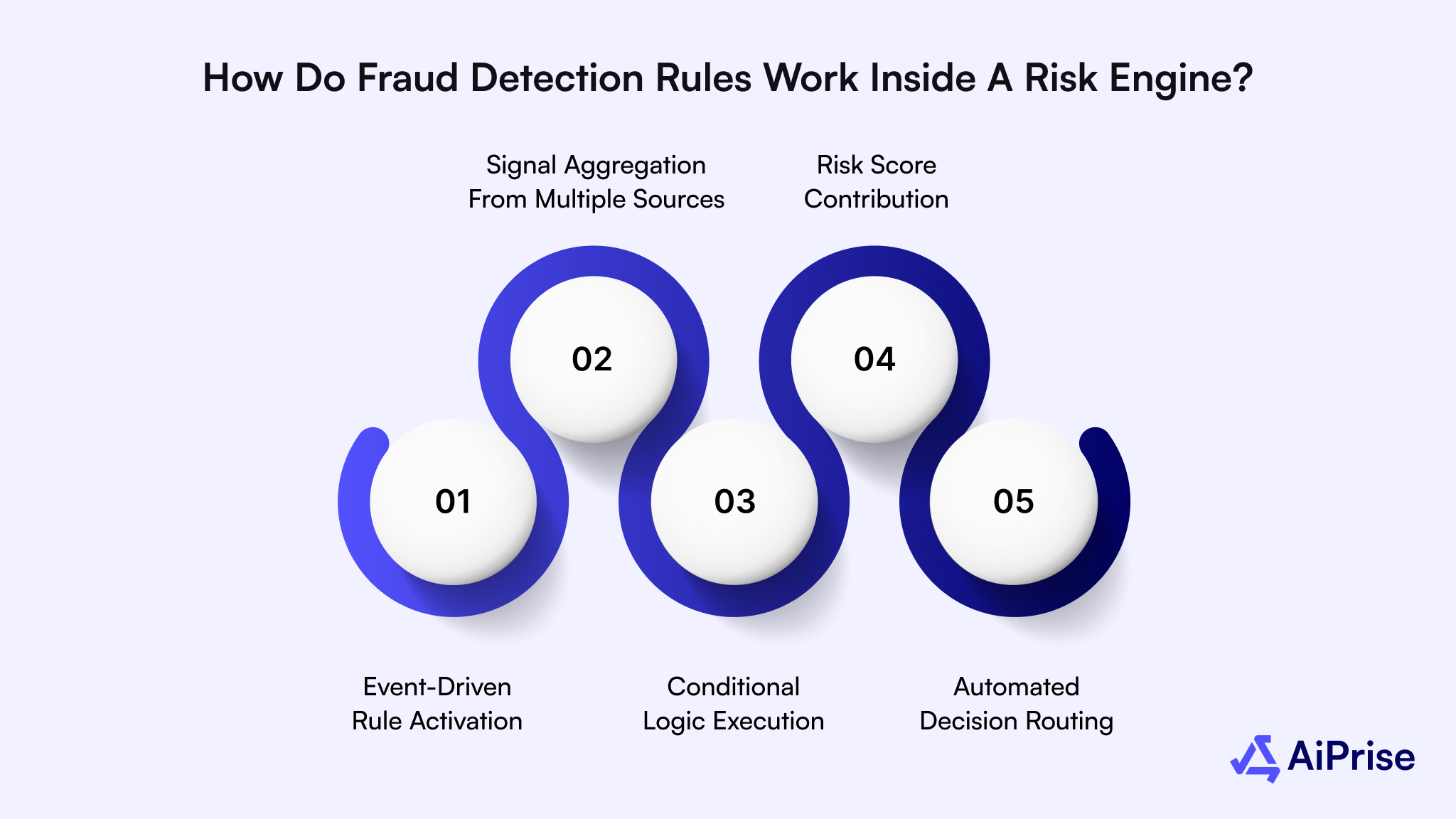
Below is how rules function within a modern risk engine.
- Event-Driven Rule Activation: Rules trigger only when specific events occur, such as onboarding, payment initiation, or profile updates. This ensures checks run where risk actually exists.
- Signal Aggregation From Multiple Sources: Inputs like device data, location context, identity attributes, and transaction details feed into the same evaluation. This creates a unified risk view per action.
- Conditional Logic Execution: Rules apply logical conditions based on thresholds and combinations. For example, a high amount plus a new account can activate stricter handling.
- Risk Score Contribution: Each rule adds or subtracts from an overall risk score. Decisions are made using the total signal strength rather than a single red flag.
- Automated Decision Routing: Based on outcomes, actions are approved, challenged, or sent for review. This keeps operations fast while reserving manual effort for edge cases.
Also Read: Common Types of Business and Financial Fraud
Understanding rule operation inside a risk engine helps clarify which types of fraud these rules can reliably detect.
What Types of Fraud Are Typically Caught by Rule-Based Systems?
Rule-based systems are most effective at detecting fraud patterns that are repeatable, measurable, and tied to clear behavioral signals. These systems work best when the fraud follows known structures rather than subtle intent shifts.
They are especially useful for catching fraud that operates on speed, volume, and inconsistency, where thresholds and conditions can reliably expose risk without deep behavioral modeling.
Below is a breakdown of common fraud types that rule-based systems detect effectively.
Are you catching repeatable fraud patterns, but struggling to rank which cases pose the highest real risk? AiPrise improves rule-based detection with Fraud Risk Scoring, adding contextual and behavioral intelligence to prioritize true fraud over noise.
While rule-based systems catch many predictable fraud patterns, relying solely on them introduces significant limitations.
What Are the Challenges of Relying Only on Rules?
Rule-based controls provide structure, but depending on them alone creates blind spots as fraud behavior evolves. When risk decisions rely only on fixed logic, attackers learn boundaries quickly and adjust their tactics.
For regulated businesses, this leads to a difficult tradeoff between blocking risk and protecting genuine users. Over time, rule-heavy systems become harder to manage, slower to adapt, and less aligned with how real customers behave across channels and regions.
Below are the key limitations you need to account for.
- Predictable Threshold Exploitation: Fixed limits teach attackers how close they can operate without triggering action. Once learned, these thresholds are deliberately avoided.
- Escalating False Positive Rates: Broad rules often block legitimate users who behave slightly outside the norm. This increases drop-offs and customer support burden.
- Operational Maintenance Load: Rules require constant tuning, testing, and cleanup. As the rule library grows, changes become risky and time-consuming.
- Limited Context Awareness: Rules evaluate conditions but miss subtle intent signals. Complex behavior often appears normal when assessed one condition at a time.
- Inconsistent Performance Across Markets: A rule that works in one region may fail elsewhere due to local behavior differences. This complicates global scaling efforts.
Also Read: Principles, Assessment, And Strategies In Fraud Risk Management
Given these limitations, combining rules with machine learning helps enhance detection and adapt to changing fraud patterns.
When Should Rules Be Combined With Machine Learning?
Rules define control, but machine learning adds interpretation. When transaction volume grows or user behavior becomes less predictable, relying on static logic limits visibility. Machine learning helps you identify risk patterns that are not obvious at the individual event level.

Below are situations where a hybrid approach delivers stronger outcomes.
- High-Volume Transaction Environments: Large volumes generate patterns that rules cannot fully capture. Machine learning surfaces correlations across thousands of events in real time.
- Rapidly Shifting Fraud Tactics: When attackers change methods frequently, models adjust faster than manual rule updates. This reduces exposure during transition periods.
- Complex User Behavior Profiles: Some users do not follow linear patterns. Machine learning interprets normal variability without triggering unnecessary blocks.
- Cross-Channel Activity Analysis: Activity spread across devices, products, or sessions becomes clearer when models connect signals that rules assess separately.
- Risk Prioritization For Operations: Models help rank alerts by likelihood of loss. This ensures review teams focus their effort where it matters most.
Also read: KYC and AML in France: How Identity Verification Works
Integrating machine learning with rules sets the stage for platforms like AiPrise to further enhance fraud rule performance and accuracy.
Top Ways AIPrise Enhances Fraud Rule Performance
Fraud rules become far more effective when they are powered by strong identity, business, and compliance intelligence. Rules alone can flag patterns, but outcomes improve when those patterns are validated against verified data and regulatory signals.
This is where deeper verification and enrichment make a measurable difference. By strengthening what rules rely on, decision accuracy improves without adding unnecessary friction or operational load.
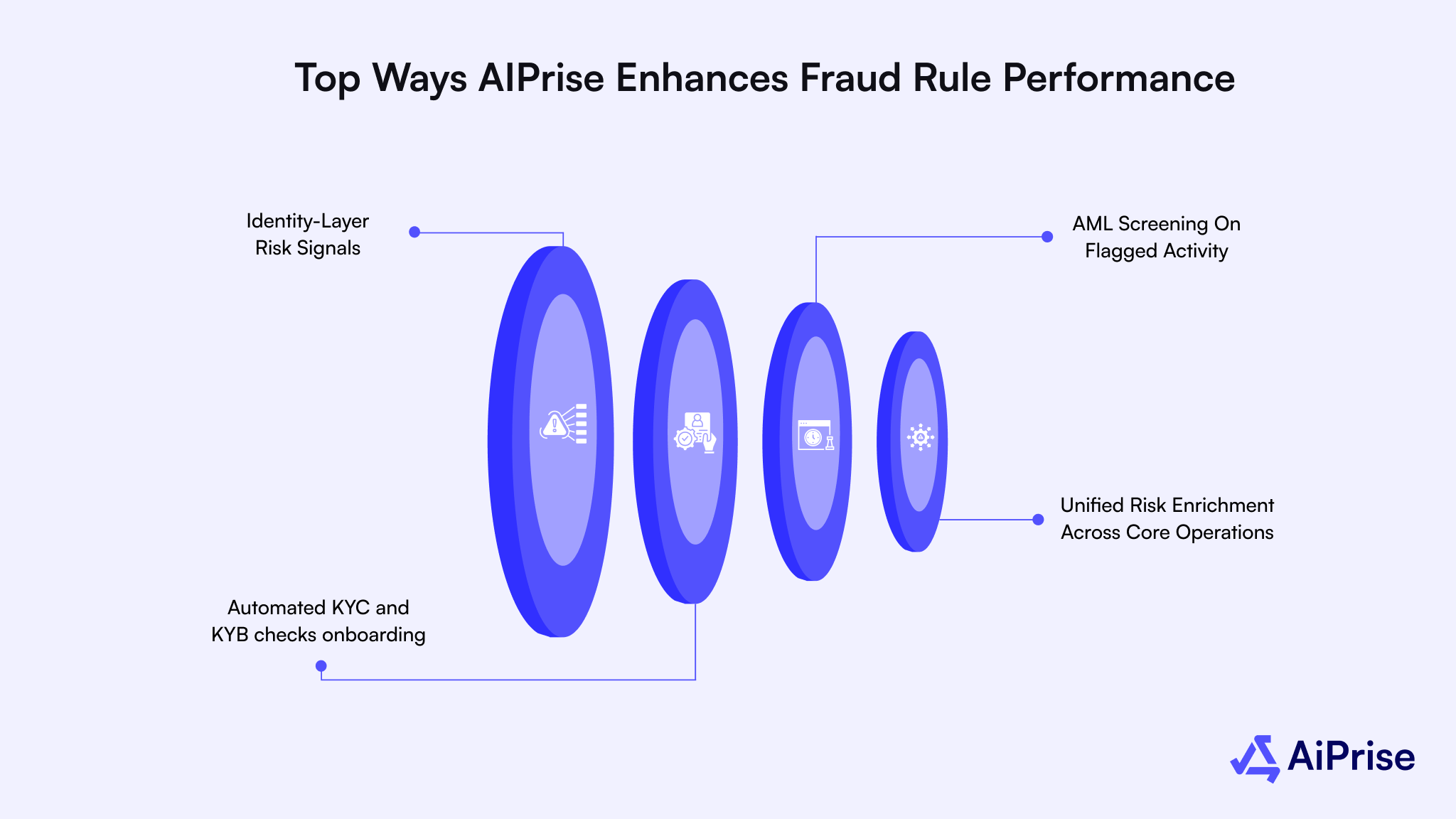
Below are the key ways rule performance improves when supported by AiPrise.
- Identity-Layer Risk Signals: Fraud rules become more precise when identity attributes are verified in real time, and AiPrise strengthens this layer by validating user identities across global data sources, reducing reliance on surface-level signals alone.
- Automated KYC and KYB checks onboarding: and transaction rules gain context when identity and business verification is automated, and AiPrise enables this by running KYC and KYB checks instantly, allowing rules to act on verified credibility instead of assumptions.
- AML Screening On Flagged Activity: Rules that surface suspicious behavior require immediate compliance validation, and AiPrise supports this by screening flagged users and transactions against sanctions, watchlists, and adverse media to reduce regulatory exposure.
- Unified Risk Enrichment Across Core Operations: Fraud detection improves when identity verification, business validation, AML screening, and global risk data work together, and AiPrise connects all four to enrich rule outcomes with consistent, compliance-ready intelligence.
By understanding how AiPrise strengthens rule outcomes, it’s clear why these enhancements are essential for a modern, effective fraud detection strategy.
Conclusion
Fraud detection rules remain a critical foundation for protecting transactions, accounts, and regulated workflows. When designed with intent and supported by the right data, these rules help control risk without slowing legitimate users or growth. Strong outcomes depend on combining clear logic with reliable verification and risk intelligence.
AiPrise strengthens this approach by enhancing rule decisions with real-time identity verification, automated KYC and KYB checks, AML screening, and global risk enrichment. This allows fraud rules to act on verified signals instead of assumptions, improving approval quality while reducing losses and regulatory exposure.
To see how stronger verification and compliance intelligence can elevate your fraud detection strategy, Book A Demo and explore how AiPrise supports smarter, scalable risk decisions.
FAQs
1. How often should fraud detection rules be reviewed and updated to stay effective?
Fraud detection rules should be reviewed at least quarterly, and more frequently in high-risk or high-volume environments. Regular reviews help account for new fraud tactics, seasonal behavior changes, and product updates. Continuous monitoring of false positives, chargebacks, and approval rates should guide when rules need adjustment.
2. What is the ideal balance between fraud prevention and customer experience?
The ideal balance is achieved through risk-based friction. Low-risk activity should pass smoothly, while higher-risk actions trigger additional checks. Overly strict rules increase drop-offs and support costs, while weak controls increase losses. Contextual rules aligned to user behavior help maintain this balance.
3. Can fraud detection rules be customized by industry or business model?
Yes, fraud detection rules should always be tailored to your industry and operating model. A crypto platform faces different risks than an ecommerce or lending business. Customization ensures rules reflect transaction types, regulatory exposure, user behavior patterns, and acceptable risk thresholds specific to your business.
4. How do fraud rules differ for onboarding versus transaction monitoring?
Onboarding rules focus on identity credibility, device stability, and initial risk signals, while transaction monitoring rules focus on behavior, value changes, and intent. Each stage carries different risk profiles, so rules must be designed separately to avoid blocking good users too early or missing fraud later.
5. What data sources are most important for building reliable fraud rules?
Reliable fraud rules depend on identity data, device signals, transaction history, location context, and behavioral patterns. External data like sanctions lists, domain reputation, and issuer intelligence also improves accuracy. Strong data quality matters more than data volume when building dependable, explainable rules.
You might want to read these...
















.png)

.png)





AiPrise’s data coverage and AI agents were the deciding factors for us. They’ve made our onboarding 80% faster. It is also a very intuitive platform.

Head of Operations





See your full compliance picture in one place
Use AI agents and global data to review businesses and users faster and more accurately
